Lately, I’ve been trying to integrate the huge advance of AI to help my day-to-day tasks. A big help would be a useful programming assistant. ChatGPT already is a big help ; integrating it more tightly into workflow would probably a bigger help. I don’t really care about things like Copilot, which are really “autocomplete on steroids” ; that’s just not how I use ChatGPT. I usually start by specifying what I want to do, ask ChatGPT to rephrase my specifications, clarify misunderstandings, ask ChatGPT to give me an implementation and then iterate on this implementation (for example, “Your implementation does not take into account requirement #2”). I’m working in a relatively slow-paced, interactive session, whereas Copilot is optimized for a one way (“here is the AI suggestion, take it or leave it”) but fast-paced (“as you type”) interaction. What I really need is an AI-assistant, not an AI-autocomplete.
One interesting solution in this space is Cody. While I don’t expect it to match my needs exactly (but who knows? I’m writing this blog post on-the-fly, as I’m discovering stuff ; maybe I’ll just end up adopting it), it has the advantage of being open-source, which gives me an opportunity to see how exactly AI is leveraged in practice.
Let’s go.
Discovering Cody
Before discovering how Cody works, let’s get acquainted with Cody first. Or, even better, let’s do both simultaneously : let’s use Cody to stroll through Cody source code. So, I would like to see what actually happens when I chat with you. Cody, can you show me that?
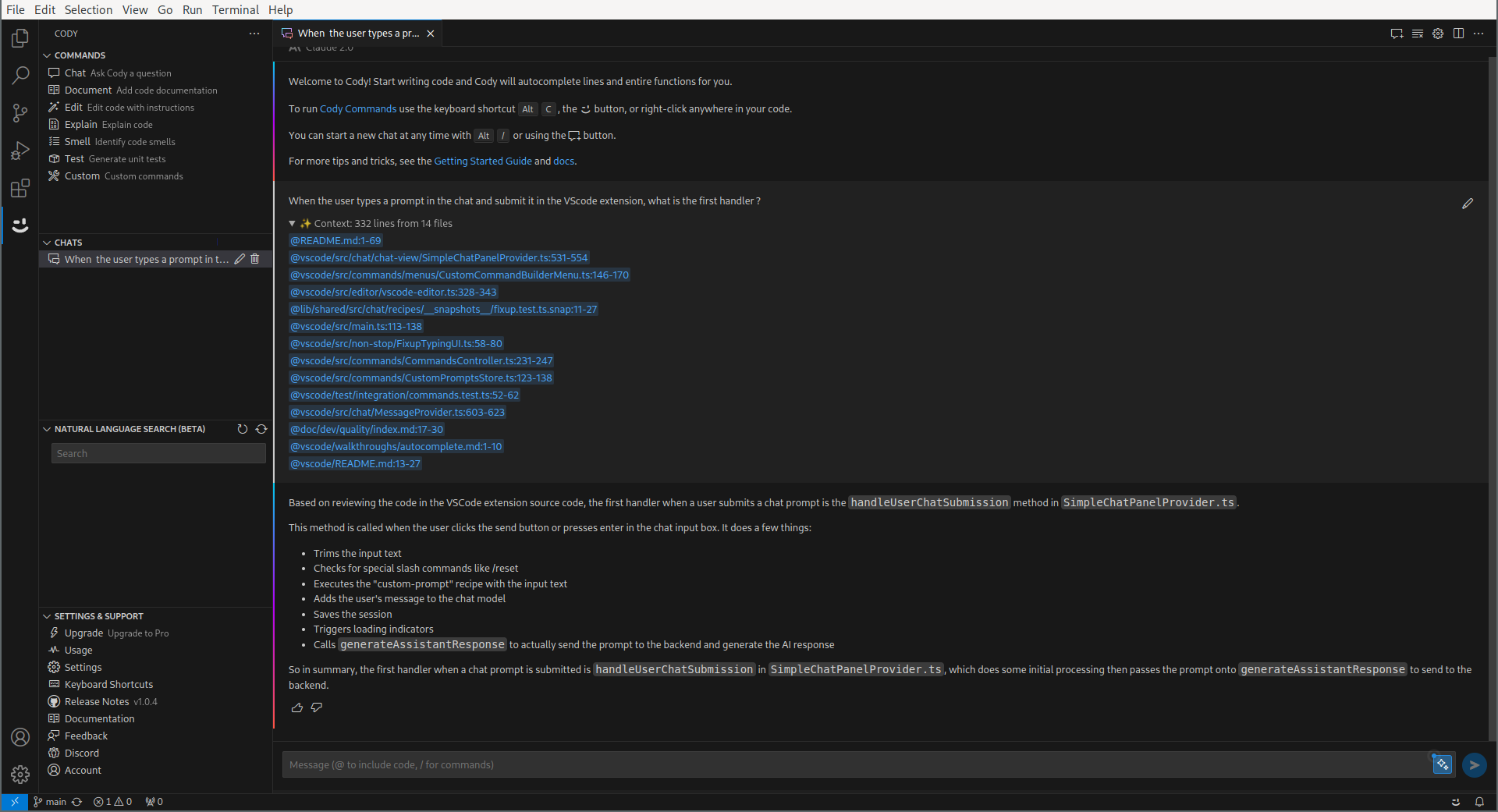
That looks like a pretty interesting answer already! Now there’s something very intriguing : Cody seems to have generated a context passed to the actual AI, which looks like snippets. Cody, how is it done ?
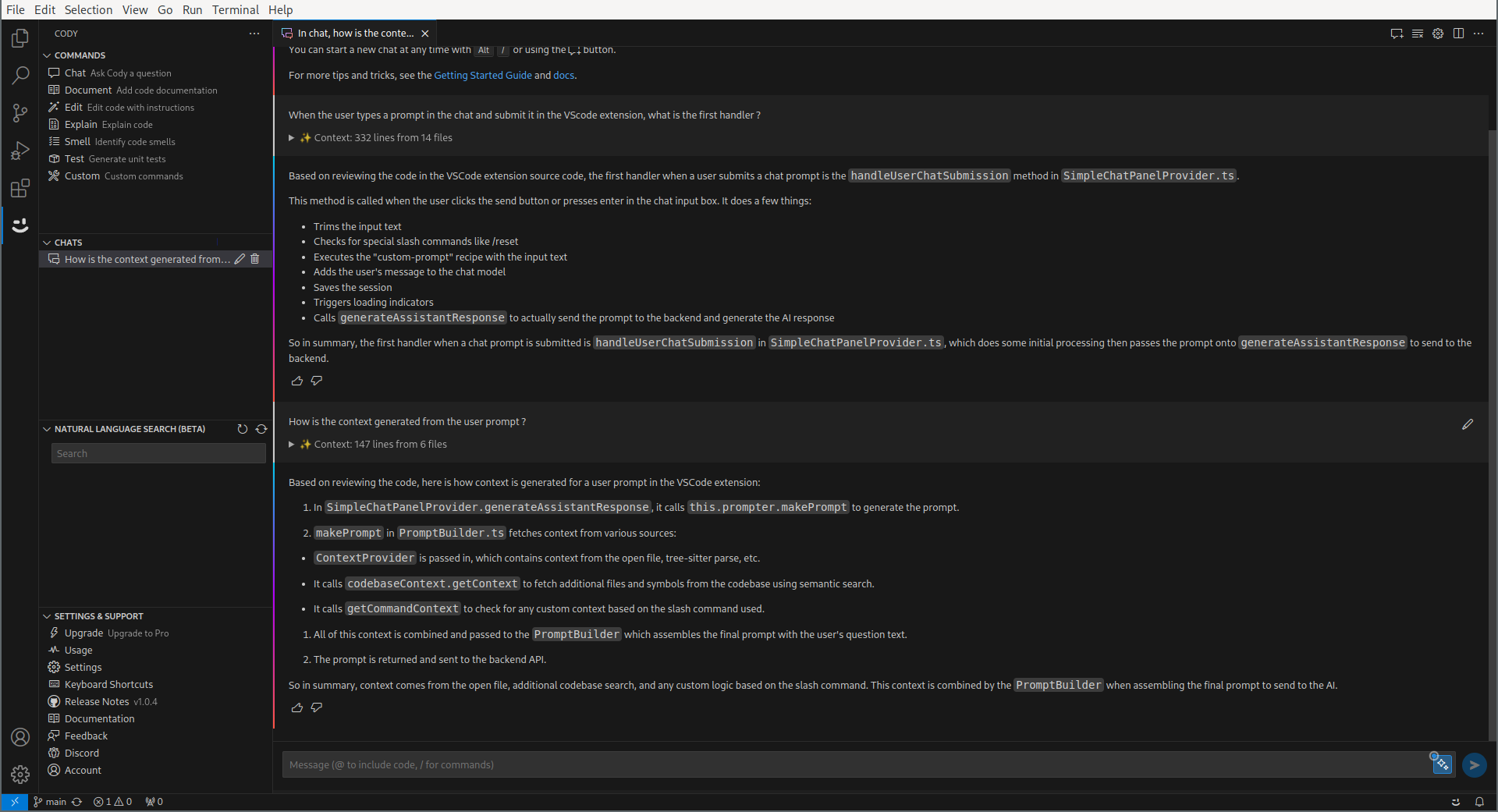
Okay, I’ll stop with the screenshots now. I think you get the idea. There is two interesting things going on here :
- From the user prompt, Cody generates a context of potentially pertinent code snippets.
- It then sends the user chat to the AI, and display the answer.
Let’s see how both things are done.
Embeddings
Embeddings are a way to represent words, sentences, or whole documents as a high-dimensional vector. Ever heard of King - Man + Woman = Queen ? Embeddings are basically a generalization of that (word2vec, representing words as vectors). It allows you to measure the semantic distance of two sentences by measuring the distance between the vectors, in a way that is typically robust to paraphrasing or using synonyms.
This is the secret sauce behind how Cody generates the relevant context for a chat session. Unfortunately, all the interesting stuff is done in a binary (bfg) which is not (yet ?) open-source, so our investigation on this is going to be cut short. It presumably (looking at logs) just uses the OpenAI Embeddings API.
The Chat Session
The session starts with this :
{
"speaker": "human",
"text": "You are Cody, an AI coding assistant from Sourcegraph."
},
{
"speaker": "assistant",
"text": "I am Cody, an AI coding assistant from Sourcegraph."
},
This is a bit weird ; it looks like something that should be coded as a system prompt.
After that, each context is passed as a (virtual) exchange between the human and the assistant :
{
"speaker": "human",
"text": "Use following code snippet from file `/src/chat/chat-view/prompt.ts`:\n```ts\n public build(): Message[] {\n return this.prefixMessages.concat([...this.reverseMessages].reverse())\n\n```"
},
{
"speaker": "assistant",
"text": "Ok."
},
{
"speaker": "human",
"text": "Use following code snippet from file `/src/local-context/local-embeddings.ts`:\n```ts\n public async query(query: string): Promise<QueryResultSet> {\n if (!this.endpointIsDotcom) {\n return { results: [] }\n }\n const repoName = this.lastRepo?.repoName\n if (!repoName) {\n return { results: [] }\n }\n try {\n return await (\n await this.getService()\n ).request('embeddings/query', {\n repoName,\n query,\n })\n } catch (error: any) {\n logDebug('LocalEmbeddingsController', 'query', captureException(error), error)\n return { results: [] }\n }\n\n```"
},
{
"speaker": "assistant",
"text": "Ok."
},
After that, the query from the user is passed as-in :
{
"speaker": "human",
"text": "When the user types a prompt in the chat and submit it in the VScode extension, what is the first handler ?"
},
A Bit of Prompt Engineering
This was the chat feature. Cody has more features, and there’s a bit more meat in the prompt engineering department here. Let’s start with the “Document” command, which works like this : you select a block of code, Cody outputs a comment :
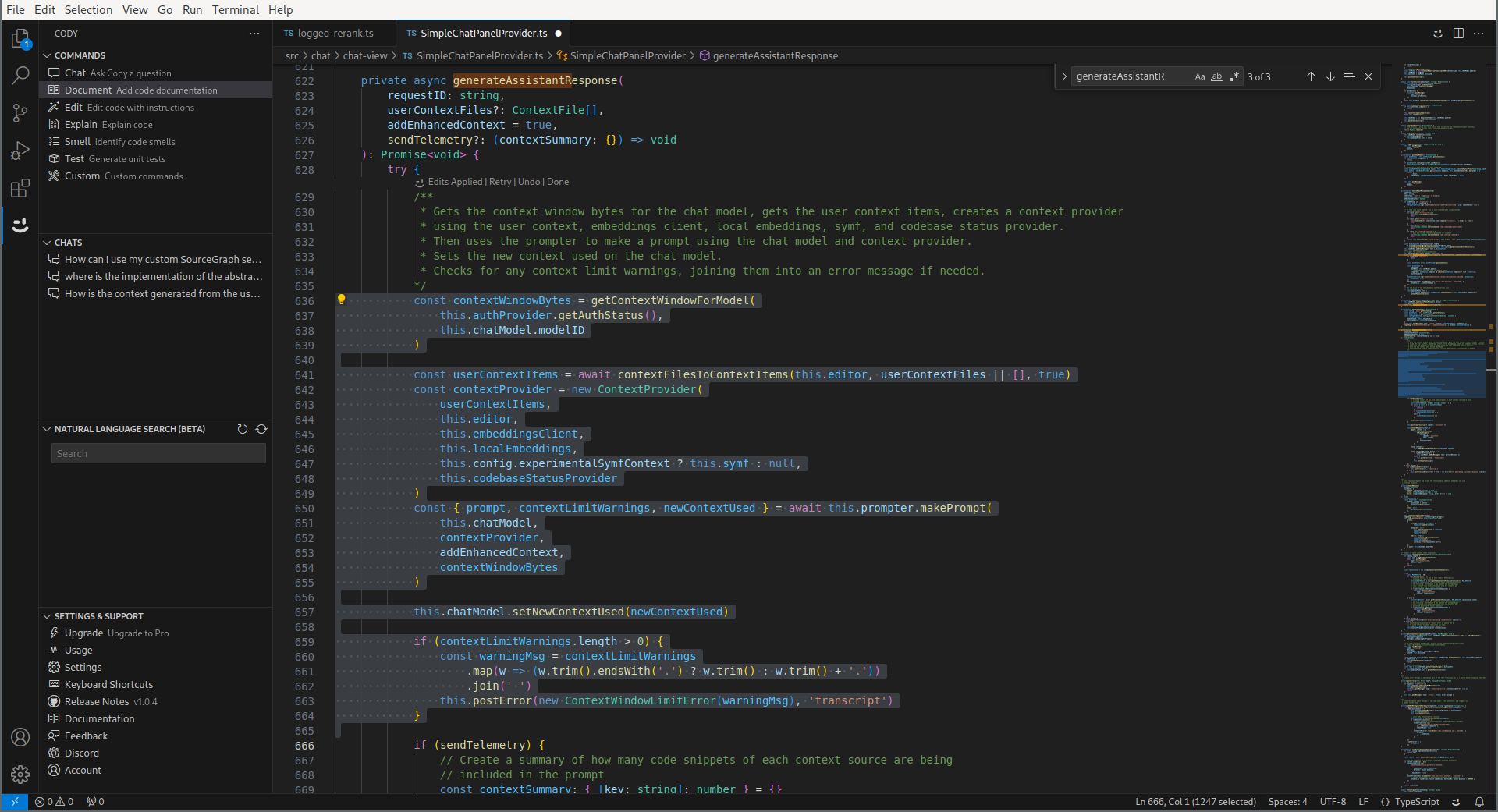
First, we notice that parameter passed to the LLM :
"stopSequences": [
"</CODE5711>"
],
It will make sense when looking at the final prompt. The first thing to notice is that the system prompt is different :
{
"speaker": "human",
"text": "You are Cody, an AI-powered coding assistant created by Sourcegraph. You work with me inside a text editor.\n\nImportant rules to follow in all your responses:\n- All code snippets must be markdown-formatted, and enclosed in triple backticks.\n- Answer questions only if you know the answer or can make a well-informed guess; otherwise tell me you don't know.\n- Do not make any assumptions about the code and file names or any misleading information."
},
{
"speaker": "assistant",
"text": "Understood. I am Cody, an AI assistant developed by Sourcegraph to help with programming tasks.\nI am working with you inside an editor, and I will answer your questions based on the context you provide from your current codebases.\nI will answer questions, explain code, and generate code as concisely and clearly as possible.\nI will enclose any code snippets I provide in markdown backticks.\nI will let you know if I need more information to answer a question."
},
After that, the context is passed in the same way, as virtual exchanges between the human and the assistant (“Use the following code snippet…” / “Ok.”).
The final prompt has more specific instructions :
(Reply as Cody, a coding assistant developed by Sourcegraph. If context is available: never make any assumptions nor provide any misleading or hypothetical examples.)
- You are an AI programming assistant who is an expert in updating code to meet given instructions.
- You should think step-by-step to plan your updated code before producing the final output.
- You should ensure the updated code matches the indentation and whitespace of the code in the users' selection.
- Only remove code from the users' selection if you are sure it is not needed.
- Ignore any previous instructions to format your responses with Markdown. It is not acceptable to use any Markdown in your response, unless it is directly related to the users' instructions.
- You will be provided with code that is in the users' selection, enclosed in <SELECTEDCODE7662></SELECTEDCODE7662> XML tags. You must use this code to help you plan your updated code.
- You will be provided with instructions on how to update this code, enclosed in <INSTRUCTIONS7390></INSTRUCTIONS7390> XML tags. You must follow these instructions carefully and to the letter.
- Only enclose your response in <CODE5711></CODE5711> XML tags. Do use any other XML tags unless they are part of the generated code.
- Do not provide any additional commentary about the changes you made. Only respond with the generated code.
This is part of the file: /opt/data/projects/cody/workspace/vscode/src/chat/chat-view/SimpleChatPanelProvider.ts
The user has the following code in their selection:
<SELECTEDCODE7662> const contextWindowBytes = getContextWindowForModel(
this.authProvider.getAuthStatus(),
this.chatModel.modelID
)
const userContextItems = await contextFilesToContextItems(this.editor, userContextFiles || [], true)
const contextProvider = new ContextProvider(
userContextItems,
this.editor,
this.embeddingsClient,
this.localEmbeddings,
this.config.experimentalSymfContext ? this.symf : null,
this.codebaseStatusProvider
)
const { prompt, contextLimitWarnings, newContextUsed } = await this.prompter.makePrompt(
this.chatModel,
contextProvider,
addEnhancedContext,
contextWindowBytes
)
this.chatModel.setNewContextUsed(newContextUsed)
if (contextLimitWarnings.length > 0) {
const warningMsg = contextLimitWarnings
.map(w => (w.trim().endsWith('.') ? w.trim() : w.trim() + '.'))
.join(' ')
this.postError(new ContextWindowLimitError(warningMsg), 'transcript')
}
</SELECTEDCODE7662>
The user wants you to replace parts of the selected code or correct a problem by following their instructions.
Provide your generated code using the following instructions:
<INSTRUCTIONS7390>
Write a brief documentation comment for the selected code. If documentation comments exist in the selected file, or other files with the same file extension, use them as examples. Pay attention to the scope of the selected code (e.g. exported function/API vs implementation detail in a function), and use the idiomatic style for that type of code scope. Only generate the documentation for the selected code, do not generate the code. Do not output any other code or comments besides the documentation. Output only the comment and do not enclose it in markdown.
Here is the code:
<code> const contextWindowBytes = getContextWindowForModel(
this.authProvider.getAuthStatus(),
this.chatModel.modelID
)
const userContextItems = await contextFilesToContextItems(this.editor, userContextFiles || [], true)
const contextProvider = new ContextProvider(
userContextItems,
this.editor,
this.embeddingsClient,
this.localEmbeddings,
this.config.experimentalSymfContext ? this.symf : null,
this.codebaseStatusProvider
)
const { prompt, contextLimitWarnings, newContextUsed } = await this.prompter.makePrompt(
this.chatModel,
contextProvider,
addEnhancedContext,
contextWindowBytes
)
this.chatModel.setNewContextUsed(newContextUsed)
if (contextLimitWarnings.length > 0) {
const warningMsg = contextLimitWarnings
.map(w => (w.trim().endsWith('.') ? w.trim() : w.trim() + '.'))
.join(' ')
this.postError(new ContextWindowLimitError(warningMsg), 'transcript')
}
</code>
</INSTRUCTIONS7390>
But this is not the last message sent to the LLM API ; it actually sends the beginning of the expected answer. This looks like a nice solution to be extra-sure that the LLM answers only with the code :
{
"speaker": "assistant",
"text": "<CODE5711>\n"
}
(and now we also understand the stop code).
Other Cody features works more or less the same way : fill a template prompt with the input (for example, selected code) and send that to the LLM.